AWS QuickSight DataSet Refresh
1. Architecture

2. Prerequired
2.1 QuickSight DataSet 생성
아무 데이터나 데이터 셋으로 생성
2.2 해당 데이터 셋 ID 확인
AWS CLI로 확인 가능
aws quicksight list-data-sets --aws-account-id xxxxxxx{ "Arn": "arn:aws:quicksight:ap-northeast-2:xxxxxxx:dataset/6bfd9fef-3376-492b-9f75-91506a2f789b", "DataSetId": "6bfd9fef-3376-492b-9f75-91506a2f789b", "Name": "**refresh_data_test_set**", "CreatedTime": 1683604683.724, "LastUpdatedTime": 1683604839.899, "ImportMode": "SPICE", "RowLevelPermissionTagConfigurationApplied": false, "ColumnLevelPermissionRulesApplied": false },2.3 Lamba Role 생성
2.3.1 Lambda to Stepfunction
- Name : lambda_to_stepfunction_role
- AWS Policy
- AWSStepFunctionsConsoleFullAccess
2.3.2 Lambda to Quicksight
- Name : lambda_to_quickight_refresh_role
- Policy
- Name : hist_quicksight_dataset_refresh_policy
Json{ "Version": "2012-10-17", "Statement": [ { "Sid": "QuickSightAccess", "Effect": "Allow", "Action": [ "quicksight:DescribeDataSet", "quicksight:PassDataSet", "quicksight:RefreshDataSet", "quicksight:ListDataSets", "quicksight:CreateIngestion", "quicksight:DescribeIngestion" ], "Resource": "*" } ] }
- AWS Policy
- CloudWatchLogsFullAccess
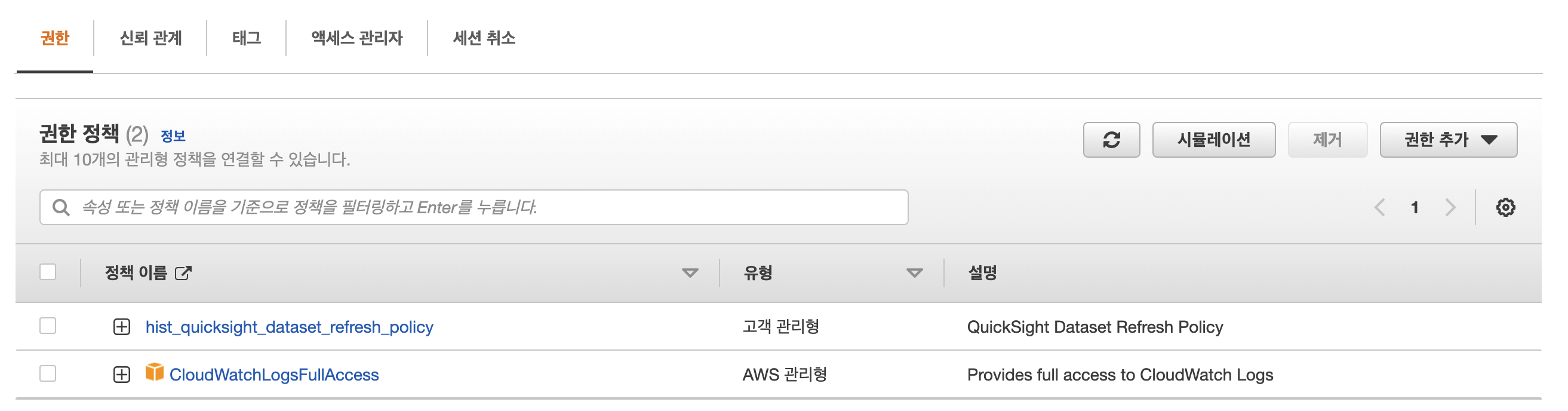
3. Lambda Refresh Quicksight
3.1 Lambda Function
- Name : lambda_quicksight_dataset_refresh
- Role : lambda_to_quickight_refresh_role
Python
import boto3
import calendar
import time
import json
# 주석 처리 된 부분은 데이터셋을 여러개 Refresh할때
# def refresh_dataset(is_wait):
# aws_account_id = "xxxxxxx"
# client = boto3.client('quicksight', region_name="ap-northeast-2")
# res = client.list_data_sets(AwsAccountId=aws_account_id)
# # filter out your datasets using a prefix. All my datasets have chicago_crimes as their prefix
# datasets_ids = [summary["DataSetId"] for summary in res["DataSetSummaries"] if "refresh_data_test_set".upper() in summary["Name"].upper()]
# ingestion_ids = []
# for dataset_id in datasets_ids:
# try:
# ingestion_id = str(calendar.timegm(time.gmtime()))
# client.create_ingestion(DataSetId=dataset_id, IngestionId=ingestion_id,
# AwsAccountId=aws_account_id)
# ingestion_ids.append(ingestion_id)
# except Exception as e:
# print(e)
# pass
# for ingestion_id, dataset_id in zip(ingestion_ids, datasets_ids):
# while True:
# response = client.describe_ingestion(DataSetId=dataset_id,
# IngestionId=ingestion_id,
# AwsAccountId=aws_account_id)
# if response['Ingestion']['IngestionStatus'] in ('INITIALIZED', 'QUEUED', 'RUNNING'):
# time.sleep(5) #change sleep time according to your dataset size
# elif response['Ingestion']['IngestionStatus'] == 'COMPLETED':
# print("refresh completed. RowsIngested {0}, RowsDropped {1}, IngestionTimeInSeconds {2}, IngestionSizeInBytes {3}".format(
# response['Ingestion']['RowInfo']['RowsIngested'],
# response['Ingestion']['RowInfo']['RowsDropped'],
# response['Ingestion']['IngestionTimeInSeconds'],
# response['Ingestion']['IngestionSizeInBytes']))
# break
# else:
# print("refresh failed for {0}! - status {1}".format(dataset_id, response['Ingestion']['IngestionStatus']))
# break
def refresh_single_dataset():
# Initialize the QuickSight client
quicksight = boto3.client('quicksight')
# Set the dataset ID that needs to be refreshed
dataset_id = '6bfd9fef-3376-492b-9f75-91506a2f789b' # Sample Dataset ID
aws_account_id = "xxxxxxxx"
# Refresh the dataset
response = quicksight.create_ingestion(
DataSetId=dataset_id,
IngestionId='refresh_data_test_set',
AwsAccountId=aws_account_id,
IngestionType='FULL_REFRESH'
)
return response
def lambda_handler(event, context):
response = refresh_single_dataset()
print(response)
return {
'statusCode': 200,
'body': json.dumps('Refresh Quicksight Dataset Done!')
}3.2 결과

4. Stepfunction
- 샘플 데이터는 Dimension 성 데이터 세트
4.1 State Mahcine Graph
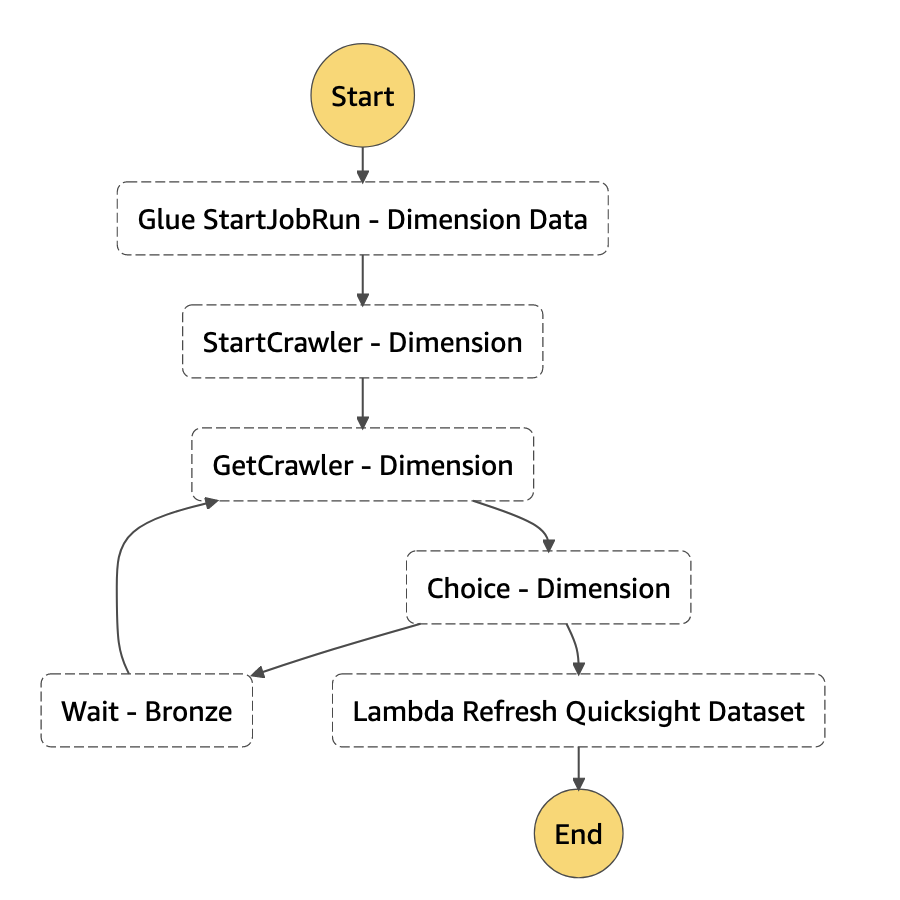
4.2 Script
- Lambda 호출할때 외부 Lambda인지 여부에 따라서 IAM Role ARN입력하는 부분이 있는데 해당 부분을 빼고 넣어야 된다. 아니면 Stepfunction Role 에 Lambda Role 권한을 추가 하여 사용할 수 있도록 해줘야됨.
Script
{
"Comment": "A description of my state machine",
"StartAt": "Glue StartJobRun - Dimension Data",
"States": {
"Glue StartJobRun - Dimension Data": {
"Type": "Task",
"Resource": "arn:aws:states:::glue:startJobRun.sync",
"Parameters": {
"JobName": "jb_hist_plan_ma_init_dimension_d2s"
},
"Next": "StartCrawler - Dimension"
},
"StartCrawler - Dimension": {
"Type": "Task",
"Parameters": {
"Name": "cr_hist_plan_ma_dimension"
},
"Resource": "arn:aws:states:::aws-sdk:glue:startCrawler",
"ResultPath": null,
"Next": "GetCrawler - Dimension"
},
"GetCrawler - Dimension": {
"Type": "Task",
"Parameters": {
"Name": "cr_hist_plan_ma_dimension"
},
"Resource": "arn:aws:states:::aws-sdk:glue:getCrawler",
"ResultPath": "$.GetCrawler",
"Next": "Choice - Dimension"
},
"Choice - Dimension": {
"Type": "Choice",
"Choices": [
{
"Variable": "$.GetCrawler.Crawler.State",
"StringEquals": "RUNNING",
"Next": "Wait - Bronze"
}
],
"Default": "Lambda Refresh Quicksight Dataset"
},
"Lambda Refresh Quicksight Dataset": {
"Type": "Task",
"Resource": "arn:aws:states:::lambda:invoke",
"OutputPath": "$.Payload",
"Parameters": {
"FunctionName": "arn:aws:lambda:ap-northeast-2:xxxxxxx:function:lambda_quicksight_dataset_refresh:$LATEST"
},
"Retry": [
{
"ErrorEquals": [
"Lambda.ServiceException",
"Lambda.AWSLambdaException",
"Lambda.SdkClientException",
"Lambda.TooManyRequestsException"
],
"IntervalSeconds": 2,
"MaxAttempts": 6,
"BackoffRate": 2
}
],
"End": true
},
"Wait - Bronze": {
"Type": "Wait",
"Seconds": 5,
"Next": "GetCrawler - Dimension"
}
}
}4.3 결과

5. Lambda to Stepfunction
- Name : lambda_oracle_etl
Script
import json
import boto3
def lambda_handler(event, context):
# TODO implement
client = boto3.client('stepfunctions')
response =client.start_execution(
stateMachineArn='arn:aws:states:ap-northeast-2:xxxxxx:stateMachine:sf_refreshdata_test_machine'
)
try:
statusCode = response["ResponseMetadata"]["HTTPStatusCode"]
except:
statusCode = 400
return{
'statusCode': statusCode
}6. API Gateway
6.1 REST API 생성
6.1.1 구축

6.1.2 프로토콜 선택

6.1.3 리소스 생성

)

6.1.4 매서드 생성
- 매서드 생성

- POST 선택
-

- Lambda 함수 선택
-

- 권한 부여
-
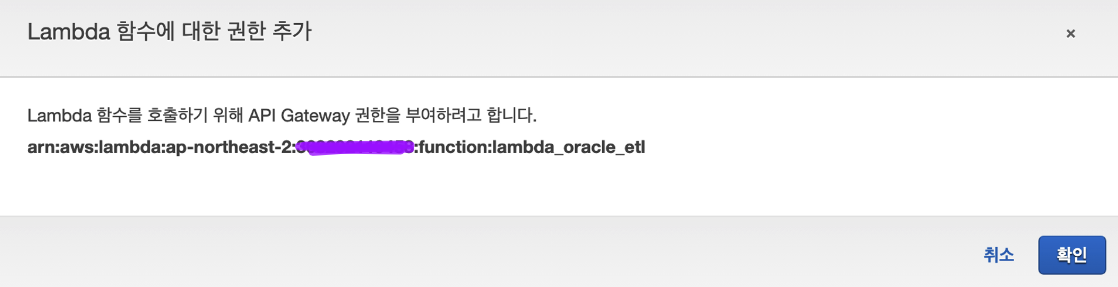
- 생성확인
-

- 테스트 수행
-

-

6.1.5 API 배포
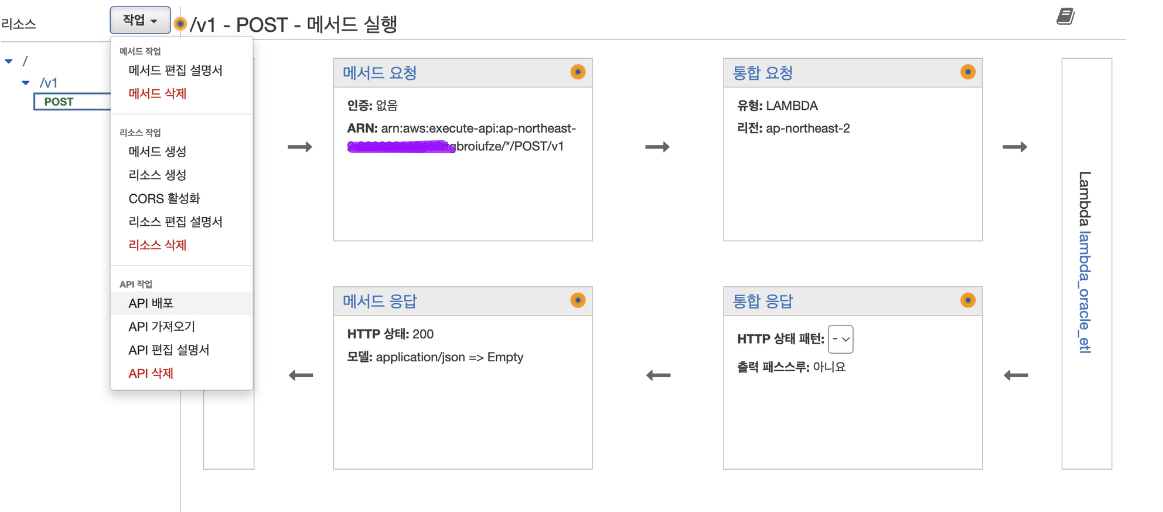
)

)
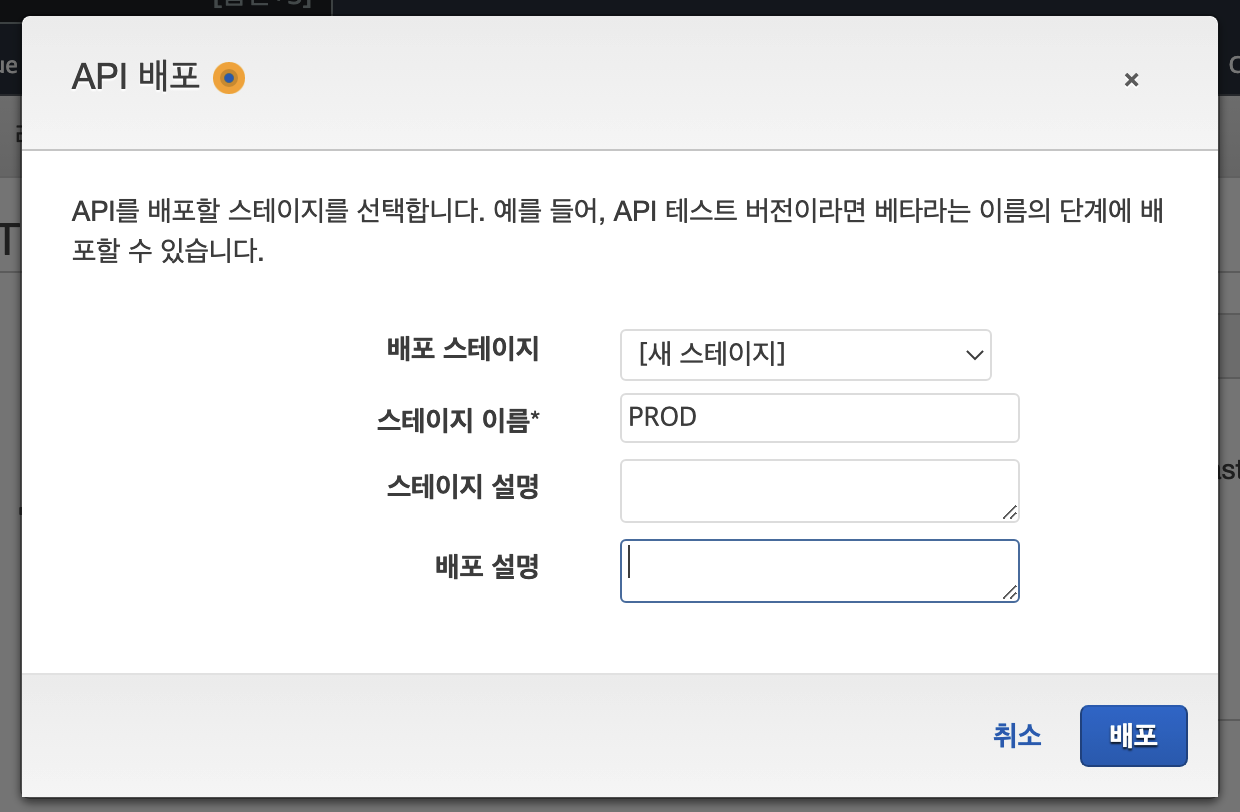
)
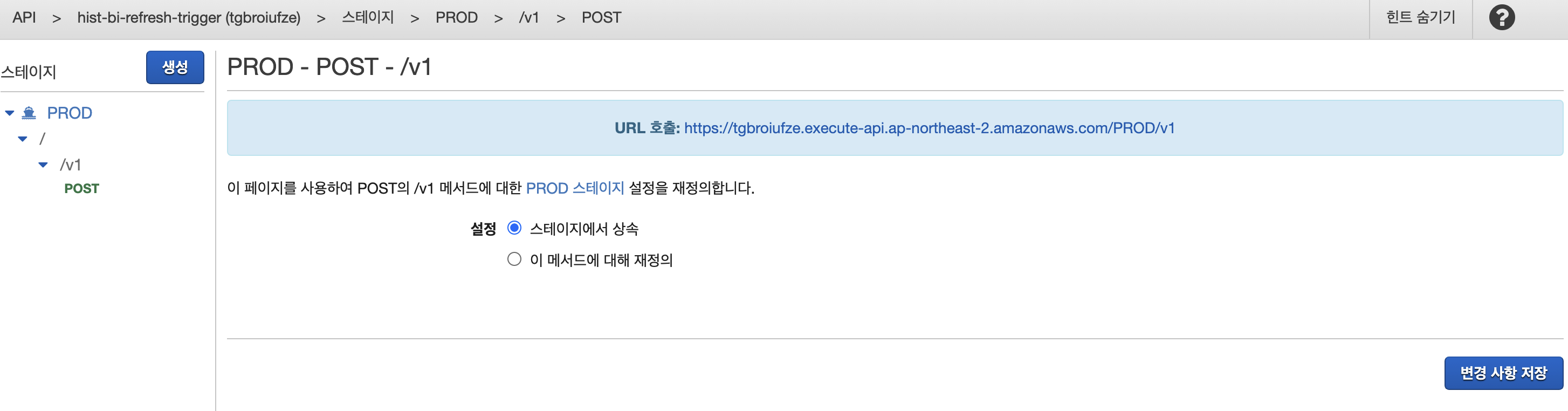
6.2 결과확인
6.2.1 API 호출
curl -XPOST https://tgbroiufze.execute-api.ap-northeast-2.amazonaws.com/PROD/v16.2.2 결과

)
