![]()
GooglePlay Reviews Crawling Retrica App(사진어플) Summary 우선 전체 평점 및 투표인원 데이터는 첫페이지 URL을 통해서 크롤링. 리뷰 : ajax 통신을 통한 크롤링. In [4]: import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import requests import urllib.request import json import requests import re from bs4 import BeautifulSoup In [17]: %matplotlib inline 1. 전체 평점 및 투표인원 첫페이지 내용 크롤링 In [5]: url = 'https://play.google.com..
![]()
Beautifulsoup & Requests Crawling을 위해서는 기본적으로 웹에서 데이터를 요청하고 요청한 데이터를 받는다 라는 것을 이해하고 있어야한다. 데이터를 달라고 요청하는 것이 우선, 그 다음이 요청한 데이터를 받아서 우리가 하고 싶은 일들을 하는 것이다. 우선 데이터를 요청하는 라이브러리부터 학습하겠다. 1. Requests In [1]: import requests 일반적인 웹 사이트의 header의 정보를 입력하지 않아도 내용을 가지고 올 수 있으나, tistory의 경우 브라우저에 따라 데이터를 접근할 수 있고 없고를 구분하는 것으로 볼 수 있다. Response 403 : Forbidden 접근 제한. 이전의 Crawling Post에 Status Code를 업로드 해놓았음. 이..
![]()
Encoding In [2]: import requests import lxml.html 꼭 알아둬야할 인코딩 ASCII EUC-KR CP949 UTF8 16진수 Hexadecimal (흔히 hex) 0~F까지 16개의 수로 한 자리를 나타냄 A B C D E F 10 11 12 13 14 15 프로그래밍에서는 0x를 앞에 붙여 표시 2진수 4자리 = 16진수 1자리 Bit 와 Byte Bit : 2진수 1자리(0 or 1) Byte = 8bit ASCII American Standard Code for Information Interchange 미국 정보 교환 표준 부호 7bit 코드: 0x00 ~ 0x7F까지 128개 000 0000(2) ~ 111 1111(2) 알파벳, 문장부호 등을 포함 첫 1b..
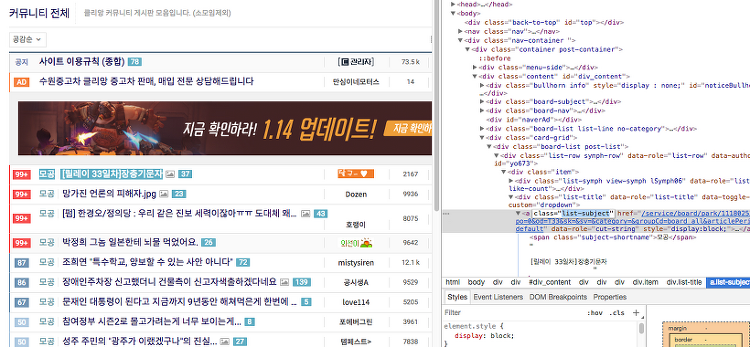
URL 분해 In [1]: from urllib.parse import parse_qs, urlparse GET 방식의 URL 요청을 분해하여 자동화하는데 손쉽게 이용이 가능하다. In [2]: result = urlparse('http://blog.naver.com/civilize?Redirect=Log&logNo=220976431562&from=section') result Out[2]: ParseResult(scheme='http', netloc='blog.naver.com', path='/civilize', params='', query='Redirect=Log&logNo=220976431562&from=section', fragment='') In [3]: result.netloc # Reque..
![]()
Web Crawling 기본적으로 텍스트 데이터를 가지고 위해서는 보통 기업 내부의 VOC 데이터 또는 텍스트 형태의 데이터를 가진 테이블을 활용하나 일반적으로 구하기 쉽거나 그렇지 않아 뉴스, SNS, 블로그 등 다양한 텍스트를 구하기 쉬운 웹의 정보를 이용한다. requests : HTTP를 위한 패키지 lxml : HTML 처리 cssselect: HTML 처리 beautiful soup : HTML 처리 HTML Method GET : 서버의 자원(resource)를 가지고 올때 사용 목록보기 글보기 다운로드 POST : 서버에 자원을 추가할때 즉, 데이터를 추가할때 글쓰기 업로드 구분이 명확하지 않아 소스와 브라우저의 개발자 도구를 통해 확인하여야 한다. HTTP Status Code 3자리수 ..
![]()
Unstructured Data 정형 데이터 : 표 등의 형태로 구조가 잡혀져 있는 데이터 비정형 데이터 : 그 외의 데이터 대표적인 예 ) 텍스트, 이미지, 비디오, 사운드 등 대부분의 데이터가 비정형 데이터이다. 특히, 텍스트 데이터 So! 텍스트 마이닝을 정리 해보고자 한다. 주로 아래와 같은 형태로 데이터를 수급한 후 분석한다. 많은 데이터들이 웹상에 존재한다. 뉴스, 정부자료, 소비자 리뷰 등 웹 스크래핑 : 자동으로 웹문서를 수집. Tokenize & TDM 토큰(token) : 분석의 단위, 주로 단위 또는 형태소 형태소 : 의미를 가지는 요소로서 가장 작은 말의 단위 단어 + 어미(한글의 경우) ex) 드세요. 들다(동사-알고 싶은 것) + 시(어미) + 어(어미) + 요(어미) 단어 - ..
노무현 대통령 vs 이명박 대통령 - 노무현 대통령과 이명박 대통령 연설문을 텍스트 마이닝을 통해 분석해봤습니다. - 자세한 설명은 아래 코드와 함께 같이 설명 하겠습니다. - 언어 : Python - 자료 : 대통령 연설문 사이트 - 해당 자료 Github 를 통해 자세한 전처리 및 크롤링 크드를 확인 하실 수 있습니다. 필요 Library In [95]: import president # Analytics Module for presidents import pandas as pd import re import wordhandle # Handling TDM & WordCount import numpy as np import matplotlib.pyplot as plt # for basic plots i..