In [1]:
import requests
- 일반적인 웹 사이트의 header의 정보를 입력하지 않아도 내용을 가지고 올 수 있으나, tistory의 경우 브라우저에 따라 데이터를 접근할 수 있고 없고를 구분하는 것으로 볼 수 있다.
- Response 403 : Forbidden
- 접근 제한.
- 이전의 Crawling Post에 Status Code를 업로드 해놓았음.
- 이전 Post
In [8]:
url = 'http://jtoday.tistory.com/80'
res = requests.get(url)
res
Out[8]:
In [9]:
res = requests.get(url, headers = header)
res
Out[9]:
In [13]:
res.headers # 이와 같이 res. 이후 Tap을 사용하게 되면 response 객체 내 어떠한 내용을 담고 있는지 확인 할 수 있다.
Out[13]:
In [14]:
res.url
Out[14]:
In [15]:
res.encoding # Encoding 정보
Out[15]:
In [16]:
res.status_code # 이 정보를 통해 Automated Crawling 을 만들게 되면 Request 성공 여부를 구분하여 만들면 된다.
Out[16]:
In [18]:
res.text[:100] # .text를 통해 html 태그를 String 형태로 확인 할 수 있다.
Out[18]:
웹 동작, GET과 POST
- GET : 서버의 자원을 요청할 때 즉, 영어 어원 그대로 무엇인가를 받을 때 사용한다.
- POST : 서버에 자원을 추가할 때 이 또한 Posting 한다와 같은 의미라고 생각하면 된다.
- 정보를 획득할 때나 업로드 할 경우 둘다 사용자는 데이터를 제공하고 그것을 통해 해당 정보를 업로드하거나 획득하게 된다.
- GET
- Idx = 3 인 정보를 테이블에서 가지고 와 주세요.
- POST
- Bookid = 3, title = '월스트리트저널 인포그래픽 가이드', author = '도나 M.윙' 의 정보를 입력해주세요.
- 주거나 또는 받거나의 행동이지만 Crawling 은 동일한 방법으로 수행 할 수 있다.
In [20]:
get_data = {'idx':3}
url = 'http://tistory.com'
res = requests.get(url,params=get_data)
In [ ]:
post_data = {'bookid':4, 'title':'월스트리트저널 인포그래픽 가이드', 'author'='도나 M.윙'}
res = requests.post(url, data=post_data) # 와 같은 방법으로 수행하면 된다.
In [27]:
from bs4 import BeautifulSoup
In [23]:
url = 'https://www.clien.net/service/group/board_all'
get_data = {'od':'T33'}
res = requests.get(url, params=get_data)
res
Out[23]:
- 이렇게 본다면 알아 보기도 힘들고 내가 원하는 정보를 볼 수도 없다.
- 속성부터 CSS, JS까지 모든 정보가 출력이 된다.
In [24]:
res.text[:200]
Out[24]:
In [30]:
soup = BeautifulSoup(res.text, 'html.parser')
type(soup)
Out[30]:
In [38]:
type(soup.get_text()) # String 값으로 변환하여 가지고 온다.
Out[38]:
In [31]:
soup.title
Out[31]:

In [34]:
soup.find('a') # 1개의 a 태그를 찾는다.
Out[34]:
In [36]:
soup.find_all('a')[:5] # a 태그를 전부 찾고 Slice[5개만]
Out[36]:
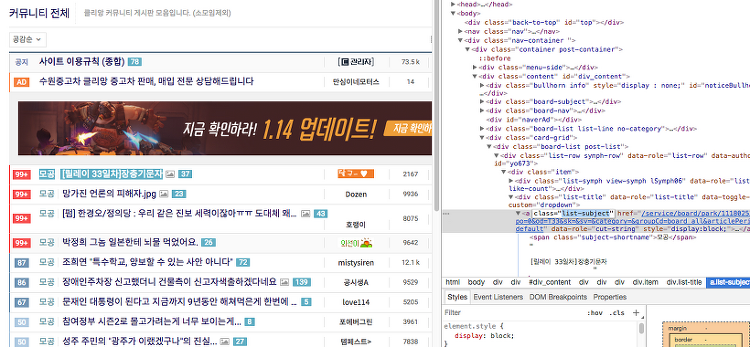
- A 태그 중 class 값을 list-subject를 가진 태그를 찾고 싶다면?
- find('태그',class_='class-Name') 를 수행
In [40]:
soup.find('a', class_='list-subject')
Out[40]:
In [42]:
soup.find_all('a', class_='list-subject')[:2]
Out[42]:
In [64]:
soup.find_all('a', class_='list-subject')[0].text
Out[64]:
In [65]:
soup.find_all('a', class_='list-subject')[0].attrs['href']
Out[65]:
In [63]:
for lists in soup.find_all('a', class_='list-subject'):
print(lists.text.replace('\t','').replace('\n','').replace('모공','') + " \n 주소 www.client.com" + lists.attrs['href'])
'BIGDATA > TEXT MINING' 카테고리의 다른 글
| [Crawling] Retrica App Review Analysis (14) | 2017.09.11 |
|---|---|
| [TEXT MINING] ENCODING, 인코딩 (0) | 2017.09.11 |
| [URL] URL 분해 및 URL Encoding (0) | 2017.09.10 |
| [Crawling] Web Crawling(크롤링) (2) | 2017.09.10 |
| [TEXT MINING] 텍스트마이닝의 기초 (TDM) (0) | 2017.09.10 |