Machine Learning의 종류 지도 학습(Supervised Learning): X와 Y의 관계를 학습시켜 X로 Y를 예측하게 하려는 경우 회귀(Regression): 연속적인 값(예: 가격)을 예측 분류(Classification): 이산적인 값(예: 성별)을 예측 비지도 학습(Unsupervised Learning): 데이터의 패턴을 나타내는 새로운 변수를 만드는 경우 군집(Clustering): 데이터를 비슷한 것끼리 무리(군집)으로 나눔 차원 축소(Dimensionality Reduction): 데이터를 적은 수의 변수로 나타냄 강화학습(Reinforcement Learning): 보상과 처벌이 존재하는 상황에서 최적의 정책을 찾으려는 경우 데이터 전처리caret Classification..
BIGDATA
데이터 시각화를 통한 탐색적 데이터 분석탐색적 데이터 분석이란? 데이터에 대한 질문을 찾는다. 데이터에 대한 시각화, 변환, 모델링으로 답을 찾는다. 답을 통해 질문을 심화하고 새로운 질문을 찾는다. ggplot2R에서 가장 널리 쓰이는 시각화 패키지 library(ggplot2) 기본 데이터 ( Diamonds ) data(diamonds) head(diamonds) caratcutcolorclaritydepthtablepricexyz 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31 0.29 Premium I VS2..

GooglePlay Reviews Crawling Retrica App(사진어플) Summary 우선 전체 평점 및 투표인원 데이터는 첫페이지 URL을 통해서 크롤링. 리뷰 : ajax 통신을 통한 크롤링. In [4]: import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import requests import urllib.request import json import requests import re from bs4 import BeautifulSoup In [17]: %matplotlib inline 1. 전체 평점 및 투표인원 첫페이지 내용 크롤링 In [5]: url = 'https://play.google.com..
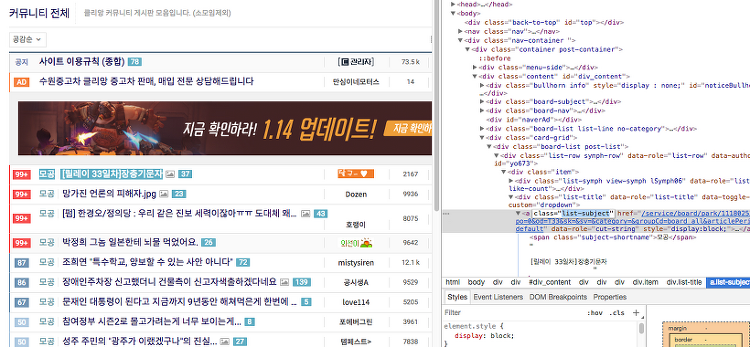
Beautifulsoup & Requests Crawling을 위해서는 기본적으로 웹에서 데이터를 요청하고 요청한 데이터를 받는다 라는 것을 이해하고 있어야한다. 데이터를 달라고 요청하는 것이 우선, 그 다음이 요청한 데이터를 받아서 우리가 하고 싶은 일들을 하는 것이다. 우선 데이터를 요청하는 라이브러리부터 학습하겠다. 1. Requests In [1]: import requests 일반적인 웹 사이트의 header의 정보를 입력하지 않아도 내용을 가지고 올 수 있으나, tistory의 경우 브라우저에 따라 데이터를 접근할 수 있고 없고를 구분하는 것으로 볼 수 있다. Response 403 : Forbidden 접근 제한. 이전의 Crawling Post에 Status Code를 업로드 해놓았음. 이..

Encoding In [2]: import requests import lxml.html 꼭 알아둬야할 인코딩 ASCII EUC-KR CP949 UTF8 16진수 Hexadecimal (흔히 hex) 0~F까지 16개의 수로 한 자리를 나타냄 A B C D E F 10 11 12 13 14 15 프로그래밍에서는 0x를 앞에 붙여 표시 2진수 4자리 = 16진수 1자리 Bit 와 Byte Bit : 2진수 1자리(0 or 1) Byte = 8bit ASCII American Standard Code for Information Interchange 미국 정보 교환 표준 부호 7bit 코드: 0x00 ~ 0x7F까지 128개 000 0000(2) ~ 111 1111(2) 알파벳, 문장부호 등을 포함 첫 1b..
URL 분해 In [1]: from urllib.parse import parse_qs, urlparse GET 방식의 URL 요청을 분해하여 자동화하는데 손쉽게 이용이 가능하다. In [2]: result = urlparse('http://blog.naver.com/civilize?Redirect=Log&logNo=220976431562&from=section') result Out[2]: ParseResult(scheme='http', netloc='blog.naver.com', path='/civilize', params='', query='Redirect=Log&logNo=220976431562&from=section', fragment='') In [3]: result.netloc # Reque..

Web Crawling 기본적으로 텍스트 데이터를 가지고 위해서는 보통 기업 내부의 VOC 데이터 또는 텍스트 형태의 데이터를 가진 테이블을 활용하나 일반적으로 구하기 쉽거나 그렇지 않아 뉴스, SNS, 블로그 등 다양한 텍스트를 구하기 쉬운 웹의 정보를 이용한다. requests : HTTP를 위한 패키지 lxml : HTML 처리 cssselect: HTML 처리 beautiful soup : HTML 처리 HTML Method GET : 서버의 자원(resource)를 가지고 올때 사용 목록보기 글보기 다운로드 POST : 서버에 자원을 추가할때 즉, 데이터를 추가할때 글쓰기 업로드 구분이 명확하지 않아 소스와 브라우저의 개발자 도구를 통해 확인하여야 한다. HTTP Status Code 3자리수 ..

Unstructured Data 정형 데이터 : 표 등의 형태로 구조가 잡혀져 있는 데이터 비정형 데이터 : 그 외의 데이터 대표적인 예 ) 텍스트, 이미지, 비디오, 사운드 등 대부분의 데이터가 비정형 데이터이다. 특히, 텍스트 데이터 So! 텍스트 마이닝을 정리 해보고자 한다. 주로 아래와 같은 형태로 데이터를 수급한 후 분석한다. 많은 데이터들이 웹상에 존재한다. 뉴스, 정부자료, 소비자 리뷰 등 웹 스크래핑 : 자동으로 웹문서를 수집. Tokenize & TDM 토큰(token) : 분석의 단위, 주로 단위 또는 형태소 형태소 : 의미를 가지는 요소로서 가장 작은 말의 단위 단어 + 어미(한글의 경우) ex) 드세요. 들다(동사-알고 싶은 것) + 시(어미) + 어(어미) + 요(어미) 단어 - ..
R_proramming_for_basic R Programming install & basic¶ R Install Basic R Programming Basic Data handling for datamining with R R & R-Studio install¶ R-Cran (R) : https://cran.r-project.org/mirrors.html R-studio (RStudio) : https://www.rstudio.com/products/rstudio/download/ Start R-studio 설치한 R-studio를 통해 수행해도 되고 Jupyter notebook에 R-Kernel을 만들어서 사용해도 무관하다. 1. Basic Calculation¶ In [1]: 3 + 4 7 In ..

RNN (Recurrent Neural Networks) 순환 신경망. 참고 Brunch Chris 송호연 유재명 교수님. PPT 우리가 문맥을 이해하거나 책을 읽을 때 바로 전의 문맥에 맞게 단어를 이해하고 내용을 생각한다. 모든 내용을 한번에 이해하는 것이 아니라 흐름(Flow)를 가지고 이해를 한다. 예전의 Neural Network에서는 ㅅ구현할 수 없었다. 이러한 것이 중요한 단서가 된 알고리즘이다. Sequence Data 하나의 단어를 가지고 이해한다고 해서 전체를 이해할 수 있는 것이 아니다. 이전의 단어들과 + 지금의 단어를 가지고 이해할 수 있다. (Time Series) NN / CNN 은 할 수 없다. 1. RNN의 구조 $X_t->A->h_t$ 순으로 값이 출력된다 그리고 $h_t..